



CPG Perfect Digital Store Audit, Automated: From a Week of Manual Work to Daily Intelligence at Global Scale
A multi-billion dollar CPG company was running its Perfect Digital Store audit manually — the entire team in a room for a week every quarter, evaluating product positioning across Amazon, Walmart, and local online retailers market by market. Rower automated the entire process using Alteryx and Python, storing scraped data in AWS S3, scoring products programmatically, and routing the remainder to Google Sheets for human review. The result: a comprehensive audit that previously took weeks once a quarter now runs in minutes — every day. Scaled globally across six countries. Unlocked millions in value.
The Problem: A Multi-Billion Dollar Brand Flying Blind on Its Most Important Channel
The Perfect Digital Store audit was the organization’s primary mechanism for understanding how its products were performing on digital shelves. The concept was sound: evaluate every product across every digital retailer against a defined scorecard — title length, brand inclusion, image count, content quality, competitive positioning, availability, search rank. Identify gaps. Fix them. Improve share of digital shelf.
The execution was unsustainable. Once a quarter, the full team assembled for a week-long manual process. Analysts visited Amazon, Walmart, and local online retailers market by market — copying data, scoring products by hand, building spreadsheets, consolidating results. In markets like Japan, China, Germany, and Mexico, this meant navigating local retailer platforms, managing language differences, and manually translating evaluation criteria across different digital environments.
By the time the audit was complete, the data was already stale. The digital shelf moves daily — a competitor updates their listing, a product loses buy box, a title gets truncated in a new marketplace. Quarterly snapshots told you what happened. They couldn’t help you respond in time to do anything about it.
A week of the full team’s time produced a snapshot that was already outdated. The digital shelf doesn’t move quarterly — it moves daily. The audit needed to move with it.
The Proof of Concept: Starting With Pet Canada
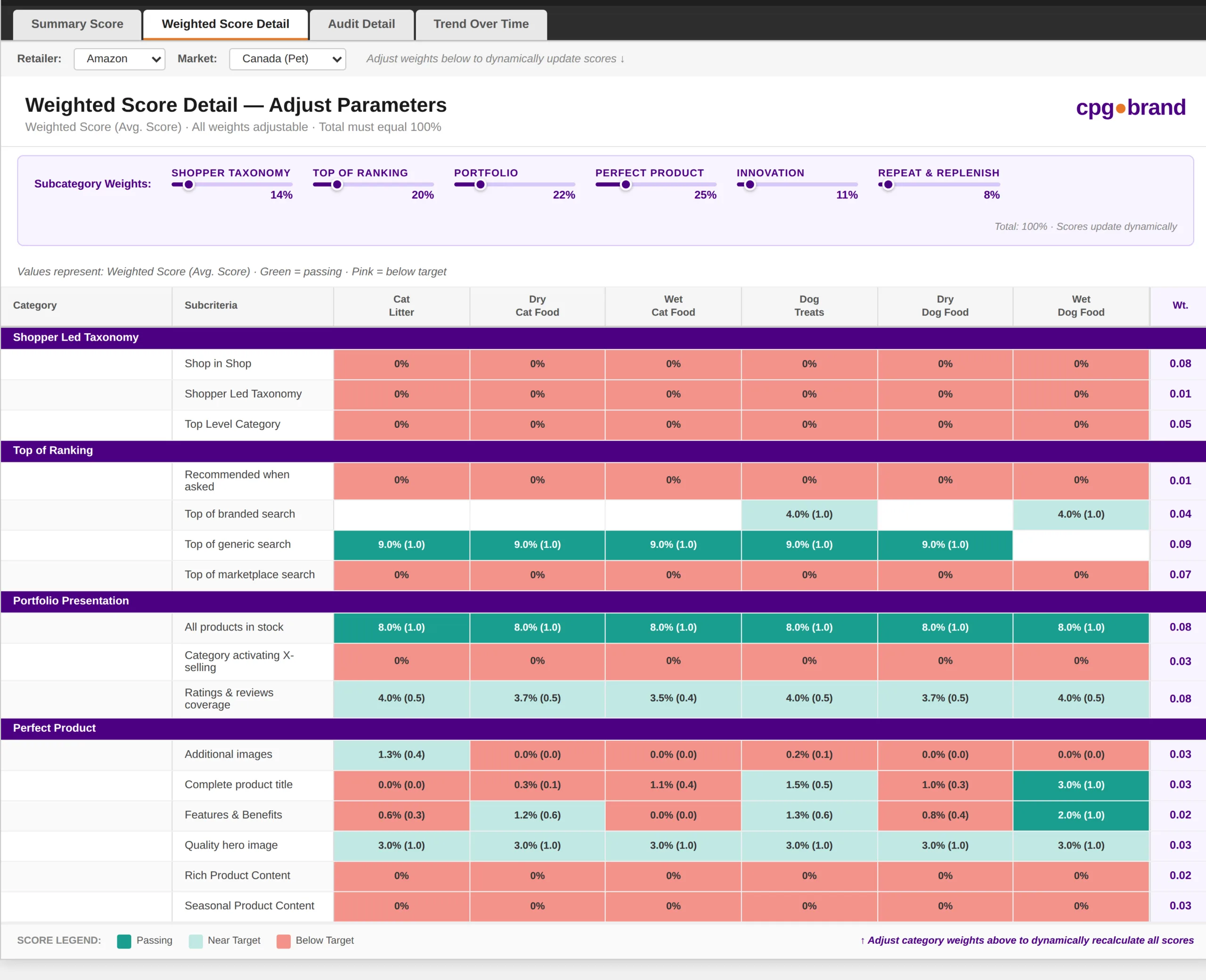
Before scaling globally, Rower proved the concept on a defined segment — Pet Canada. The objective was to demonstrate that the full manual process could be automated without sacrificing the completeness or integrity of the audit scoring methodology.
The Pet Canada pilot established the core architecture that would eventually scale across six countries and multiple product categories:
Custom Python scrapers built for each retailer — Amazon Canada, Walmart Canada, and local online retailers — extracting product data including titles, images, availability, pricing, search rank, and content fields at scale.
All scraped data stored in AWS S3 buckets — structured for retrieval, versioned for trend tracking, and accessible by the Alteryx processing layer downstream. Historical data retained for performance trending over time.
Alteryx workflows pulled data from S3 and applied the audit scoring logic automatically — title length, brand name inclusion, image count, keyword presence, availability status, and other objectively measurable criteria. Scored without human intervention.
What couldn’t be scored programmatically — image quality, lifestyle photography, content tone, packaging alignment — was routed automatically to Google Sheets. The team scored only the questions that required human judgment. Alteryx pulled those responses back and incorporated them into the final audit score.
The Scoring Architecture: What Got Automated and What Didn’t
One of the most important design decisions in this project was understanding the boundary between what a machine could score reliably and what genuinely required human judgment. Getting this wrong in either direction breaks the audit — over-automate and quality scores become meaningless, under-automate and you haven’t solved the problem.
Programmatically scored — Alteryx + Python
Title length — character count against platform-specific thresholds. Amazon, Walmart, and local retailers each have different optimal title lengths. Scored automatically per platform.
Brand name inclusion — does the product title contain the brand name in the right position? Regex matching across all scraped titles, at scale, every day.
Image count — number of product images versus the platform’s ideal count. Scraped from the listing, scored automatically against the standard.
Keyword presence — required keywords in titles, bullets, and descriptions. Checked against a defined keyword library per product category.
Availability and buy box status — in stock, out of stock, won or lost buy box. Tracked daily across all retailers and markets.
Bullet point count and length — how many bullets, are they within platform length limits, do they hit key benefit claims?
Human-reviewed via Google Sheets — routed by Alteryx
Image quality — is the hero image on a clean white background? Does it meet brand standards? Does it show the product clearly? A score, not a count.
Lifestyle imagery — does the image set include appropriate lifestyle photography for the product category? Judgment required.
Content tone and brand voice — does the copy read on-brand? Is it appropriate for the market and retailer context?
Local market appropriateness — in Japan, China, Germany, and Mexico, does the content reflect local consumer expectations and regulatory requirements?
The hybrid model was the key insight. It eliminated the work that machines do better than people — repetitive, rule-based, high-volume — while preserving human judgment for the questions that genuinely require it. The team stopped spending time counting images and started spending time evaluating them.
Scaling Globally: US, Canada, Japan, China, Germany, Mexico
After proving the model on Pet Canada, Rower scaled the architecture across six countries and multiple product categories. Each market required building new scrapers for local retailer platforms, adapting scoring logic for local standards, and handling language and character encoding differences in the data processing layer.
The Alteryx workflow was designed to be modular — market-specific configurations sat above a shared processing core. Adding a new market meant building the scraper and configuring the market parameters, not rebuilding the scoring engine from scratch. The Google Sheets workflow for human review was adapted for each market’s language requirements.
What had previously required the entire team in a room for a week — once a quarter — now ran automatically every day. The team’s time shifted from execution to insight: reviewing scores, identifying trends, prioritizing fixes, and measuring improvement.
From Quarterly Snapshots to Daily Intelligence
The operational transformation was immediate and measurable. The frequency shift — from quarterly to daily — changed what the organization could do with the information entirely.
One week. Full team. Four times a year. By the time results were available, the digital shelf had moved. Issues that surfaced in January weren’t addressed until the April audit confirmed them.
Scores updated daily. Drops in availability, title changes, image count decreases — flagged the same day they occur. The team responds in hours, not months.
What Changed
Weeks to minutes — a week-long manual process runs automatically in minutes. The team never assembles for a manual audit again.
Quarterly to daily — monitoring frequency went from four times a year to every day across all markets and retailers simultaneously.
Consistent, objective scoring — the same criteria applied the same way to every product, every market, every day. No variation based on who’s doing the audit.
Global scale from a single platform — US, Canada, Japan, China, Germany, and Mexico scored through the same architecture with market-specific configuration.
Millions in value unlocked — faster identification of digital shelf gaps, faster remediation, and daily visibility into competitive positioning translated directly into recovered revenue and improved search rank.
A fully automated Perfect Digital Store audit platform — Python scrapers feeding AWS S3, Alteryx processing and scoring, Google Sheets handling human review, all integrated into a single daily score across Amazon, Walmart, and local retailers in six countries. What took the full team a week every quarter now runs in minutes every day. The organization moved from quarterly snapshots to real-time digital shelf intelligence — and unlocked millions in value in the process.